

As the adoption of large language models (LLMs) accelerates across industries, managing their lifecycle, optimizing prompts, and ensuring reliable performance has become crucial. This has given rise to the domain of LLM Ops (Large Language Model Operations) and Prompt Engineering. From versioning and monitoring to fine-tuning and orchestrating workflows, specialized tools are emerging to help developers, researchers, and businesses get the most out of generative AI. , large language models (LLMs) are no longer experimental tools—they are mission-critical infrastructure powering modern applications. From customer support to internal knowledge management, businesses increasingly rely on AI that is reliable, scalable, and context-aware. LLM Ops (Large Language Model Operations) and Prompt Engineering are emerging as essential disciplines, helping teams manage workflows, ensure output quality, and reduce operational risks.
1. PromptLayer
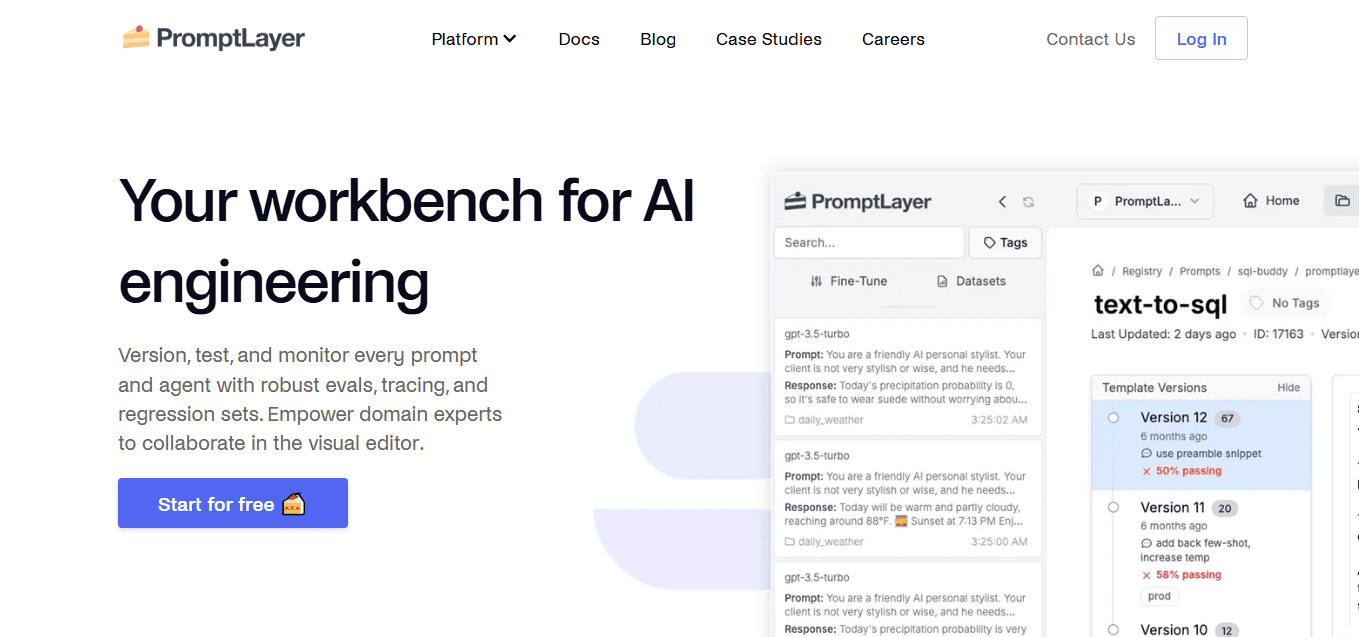
PromptLayer pioneered the idea of prompt version control. With full visibility into prompt history, A/B testing, and collaborative prompt reviews, it’s invaluable for Backend Developers, AWS Developers, and SaaS Developers managing iterative prompt workflows in real-world applications.
Key Features:
- Version history and rollback
- OpenAI API integration
- Prompt comparison and analytics
- Team collaboration
Pros:
- Python SDK for easy integration (ideal for Python Developers)
- Lightweight and intuitive for quick setup
- Excellent for testing by software testers
Cons:
- Limited to OpenAI models
- No native support for prompt tuning
Who Should Use It?
Great for Full Stack Developers, NodeJS Developers, and Django Developers building with GPT-4 APIs.
2. LangChain
LangChain is the gold standard for developers building agentic and RAG-style architectures. MEAN Stack Developers, MERN Stack Developers, and AngularJS Developers can integrate external tools, documents, or APIs to orchestrate advanced LLM logic flows.
Key Features:
- Tool calling and chain building
- Embedding/vector database integration (e.g., ChromaDB, Pinecone)
- Prompt templating and dynamic inputs
- Multi-agent orchestration
Pros:
- Active OSS community
- Highly customizable for Open Source Developers
- Works well with Spring Boot, Flask, and ExpressJS backends
Cons:
- Steep learning curve
- Requires Python proficiency
Who Should Use It?
Perfect for Backend Developers, Spring Boot Developers, and JavaScript Developers developing intelligent, contextual LLM applications.
3. Weights & Biases (W&B) for LLMOps
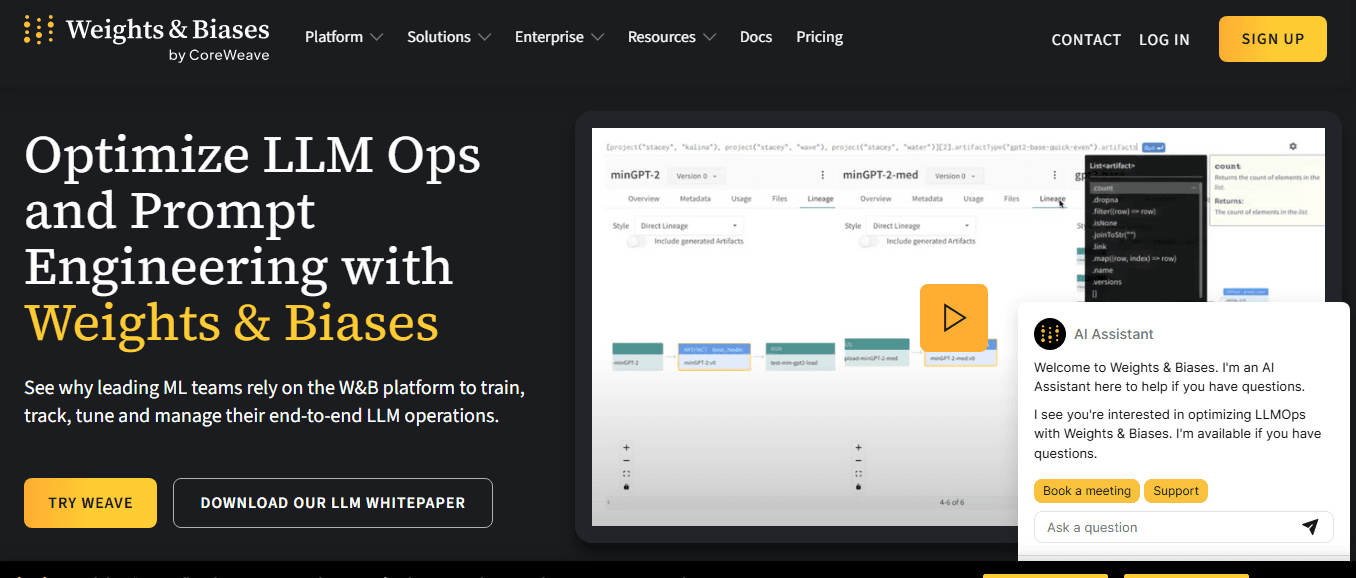
For Mobile App Developers and Android Developers deploying LLMs inside apps, W&B offers robust experiment tracking, token usage insights, and cost control. It’s also powerful for Flutter Developers needing production visibility into AI responses.
Key Features:
- Token usage heatmaps
- LLM prompt-output comparisons
- Hugging Face + OpenAI integrations
- Real-time monitoring dashboards
Pros:
- Excellent for DevOps Engineers managing ML pipelines
- Collaborate across UI/UX and testing teams
- Enterprise-grade security and version control
Cons:
- Requires a proper setup
- Not focused purely on prompt creation
Who Should Use It?
Ideal for DevOps Engineers, iOS Developers, Flutter Developers, and React Native Developers operating in production environments.
4. PromptHub
Inspired by GitHub, PromptHub offers a collaborative platform where Software Developers, WordPress Developers, and Shopify Developers can store, categorize, and test their prompts.
Key Features:
- Prompt tagging, search, and metadata
- Role-based access control
- Multi-model test environments
- Versioning and feedback tracking
Pros:
- No-code UI for fast iteration
- Perfect for distributed developer teams
- Great fit for Mobile App and Web Developers
Cons:
- No native chaining
- Doesn’t support custom model training
Who Should Use It?
Useful for Frontend Developers, HTML5 Developers, and Tailwind CSS Developers collaborating on AI content workflows.
5. TruLens
TruLens supports customizable metrics, making it a favorite among UI/UX Designers and testers. Developers can collect user feedback and automatically flag hallucinated or biased responses.
Key Features:
- Relevance, safety, and coherence scoring
- Visual output comparison
- Model performance dashboards
- Recommendations for prompt improvement
Pros:
- Easy to integrate into QA pipelines
- Compliant for regulated industries (finance, healthcare)
- Custom metric support for software testers and analysts
Cons:
- Not built for prompt generation
- Requires datasets for full functionality
Who Should Use It?
Essential for QA teams, UI UX Designers, Joomla Developers, and regulated product teams.
6. Promptable
Promptable allows rapid previewing and debugging of prompts across models like Claude, GPT-4, and LLaMA. SaaS Developers, Shopify Developers, and PHP Developers love its productivity-focused UI.
Key Features:
- Prompt editing + benchmarking
- Model switching and input variations
- Reusable prompt components
- Integrated evaluation
Pros:
- Quick UI-based prompt iterations
- Works well for product-led teams
- SaaS-friendly
Cons:
- Limited free tier
- SaaS-based (not ideal for offline-only teams)
Who Should Use It?
Great for PHP Developers, SaaS Builders, and ReactJS Developers working on AI-powered platforms.
7. Helicone

Helicone is like Datadog for AI. Acting as a proxy layer, it gives Backend Developers, AWS Developers, and DevOps Engineers full observability into every prompt/response cycle — including token cost, latency, and user logs.
Key Features:
- Request logs with payload inspection
- Rate limiting and access controls
- Endpoint-level analytics
- Cost monitoring
Pros:
- No code changes needed
- Detailed analytics for decision-makers
- Scales with enterprise-grade apps
Cons:
- OpenAI-centric
- No prompt creation features
Who Should Use It?
Perfect for Backend Engineers, DevOps Engineers, ExpressJS Developers, and NodeJS Developers managing production AI stacks.
8. Replit Ghostwriter Prompt IDE
Replit’s IDE now includes prompt engineering tools that allow JavaScript Developers, TypeScript Developers, and ViteJS Developers to write and test prompts alongside their codebase.
Key Features:
- Prompt execution inline with code
- Prompt-output diffing
- Contextual suggestions
- Git-style version control
Pros:
- Streamlined for code-focused teams
- Natural fit for frontend/backend collaboration
- Excellent for Full Stack and Open Source Developers
Cons:
- Requires Replit environment
- Not for non-coders
Who Should Use It?
Ideal for Java Developers, TypeScript Developers, and ReactJS Developers building LLM apps directly in the cloud IDE.
9. LlamaIndex (formerly GPT Index)
LlamaIndex excels at bridging data silos and LLMs. Mobile App Developers, Magento Developers, and Backend Developers use it to power RAG systems with PDFs, APIs, and SQL.
Key Features:
- Document parsing and embedding
- Advanced indexing methods
- Seamless LangChain integration
- API + file system support
Pros:
- Handles large document sets
- Key part of scalable LLM pipelines
- Perfect for knowledge management apps
Cons:
- Needs Python scripting
- Not UI-friendly for non-devs
Who Should Use It?
Valuable for Python Developers, Django Developers, and Backend Developers building AI knowledge apps.
10. Chainlit
Chainlit is like Streamlit but optimized for LLMs. Frontend Developers, VueJS Developers, and AngularJS Developers can use it to wrap prompt workflows in interactive UIs within minutes.
Key Features:
- UI for prompt experimentation
- LLM response rendering
- Debug console and user inputs
- Integrates with LangChain, LlamaIndex
Pros:
- Fast to deploy
- Open-source
- Ideal for MVP testing
Cons:
- Limited prebuilt UI components
- Requires Python backend
The Future of LLM Ops and Prompt Engineering – Building Smarter AI Workflows
As we stand in the midst of an AI revolution, LLM Ops and Prompt Engineering are quickly maturing into their own fields. Just as DevOps transformed the software development lifecycle, and MLOps brought order to the chaos of machine learning pipelines, LLM Ops introduces operational clarity, reliability, and accountability to generative AI. Likewise, prompt engineering has become a skillset in high demand, blurring the lines between art and science — part programming, part UX design, part linguistic intuition.
1. Prompt Engineering: No Longer Just Crafting Queries
The myth that prompting is as simple as “just asking ChatGPT” is being debunked daily. Today’s AI teams realize that prompts are the interface between human intent and machine logic. Prompt engineers are solving business problems through iterative language tuning, structured chaining, and output scoring. Tools like PromptLayer, PromptHub, and Promptable cater precisely to this emerging professional role.
What These Tools Bring:
- Versioning & Audit Trails: With tools like PromptLayer and PromptHub, teams can now track changes, annotate decisions, and trace performance regressions back to individual prompts.
- Prompt Reusability: Creating a central prompt library avoids "prompt sprawl" — the proliferation of slightly modified prompts in notebooks, code, and emails.
- Live Experimentation: Promptable allows real-time testing of different prompts across models and scenarios, shortening the feedback loop from idea to result.
2. LLM Ops Is Becoming Essential for Scaling AI Applications
The moment an AI prototype becomes a product, the need for LLM Ops kicks in — how to monitor costs, ensure prompt accuracy, detect anomalies, and route between models becomes crucial. Just like any production system, AI systems need observability, security, and scaling.
This is where tools like Helicone, Weights & Biases, TruLens, and LangChain stand out.
Operational Focus Areas:
- Cost & Token Management (Helicone): Monitoring token usage prevents bill shock and helps optimize prompt structure.
- Monitoring and Evaluation (W&B, TruLens): With continuous evaluation loops, teams can improve model reliability and explainability.
- Complex Prompt Workflows (LangChain): The ability to orchestrate tool calling, memory, and conditional logic is a leap from basic prompting.
Challenges They Solve:
- You can’t evaluate success in LLMs just through accuracy — response helpfulness, relevance, tone, and fairness must be monitored.
- Real-world prompts often require retrieval augmentation, contextual embedding, and fallback routing — all operational decisions.
- In regulated sectors (finance, healthcare), audit trails, privacy, and evaluation aren’t optional — they’re core requirements.
3. Retrieval-Augmented Generation (RAG): Bringing Context to Prompts
As LLMs are often trained on stale data, augmenting them with fresh, structured, and private knowledge is crucial. This is where tools like LlamaIndex and LangChain shine — by bridging LLMs to business-specific context (documents, databases, APIs).
The RAG Stack in Action: LlamaIndex handles ingestion, chunking, indexing, and querying of large knowledge bases.
LangChain orchestrates multi-step chains where an LLM might:
- Retrieve a document,
- Generate a query,
- Parse the result,
- Generate a human-readable output.
This is a huge step forward from relying on static prompts alone.
Use Cases of RAG:
- Customer Support Bots using real-time product manuals
- Internal Knowledge Assistants for enterprises
- Domain-Specific Q&A Apps for law, medicine, or finance
4. Who Needs What? Matching Tools to Roles
Let’s break down who benefits most from which tool, based on roles and goals: No single tool solves everything. Teams must create a stack of tools tailored to their phase (prototype vs. production) and their role (engineer vs. product).
Tools as per different team sizes, stages, or use cases:
- Startup / Prototype: Promptable + LangChain
- Mid-size Product Team: PromptLayer + W&B + Helicone
- Enterprise / Regulated Industry: TruLens + LlamaIndex + Helicone
5. The AI Development Lifecycle Has Changed
The AI development lifecycle is no longer linear. It’s a continuous loop that includes:
- Prompt Design
- Model Selection & Tuning
- Evaluation (Auto + Human-in-the-Loop)
- Monitoring in Production
- Version Control & Iteration
These tools fill in different gaps along this cycle:
Lifecycle Phase | Tools That Excel |
| Prompt Design | Promptable, PromptLayer |
| Iteration & Testing | PromptHub, TruLens |
| Deployment & Routing | LangChain, Chainlit |
| Monitoring | Helicone, W&B |
| Evaluation | TruLens, W&B |
| Data-Augmentation/RAG | LlamaIndex, LangChain |
Each phase requires specialized tools, but the future likely holds greater integration across the stack — with end-to-end LLM DevOps platforms emerging.
6. Limitations and Open Challenges
While these tools are powerful, they are not without gaps:
A. Fragmented Tooling Ecosystem
There is no “one-size-fits-all” platform. Teams often end up stitching together multiple tools — from LangChain to W&B to PromptLayer — which can create integration and compatibility issues.
B. Vendor Lock-In
Some tools, especially those tied closely to OpenAI or proprietary platforms, can limit portability across models like Claude, Mistral, or open-source LLaMA variants.
C. Lack of Standardization
Prompt formats, evaluation metrics, and performance benchmarks still lack universal standards. This affects reproducibility and collaboration across organizations.
D. Ethics, Bias & Safety Evaluation
Most tools still lag behind in offering robust checks for bias, toxicity, hallucination, and factual consistency — crucial for responsible AI deployment.
7. Future of LLM Ops and Prompt Engineering
Looking ahead, we foresee several trends shaping this field:
A. Auto-Prompting and Optimization
AI-powered prompt tuning — where systems evolve prompts automatically based on performance — will become mainstream. Think of it as A/B testing for prompts at scale.
B. Agent-Based Workflows
LangChain, ReAct, AutoGPT, and others are driving momentum for AI agents that reason, plan, and act. LLM Ops tools will adapt to monitor and debug these complex chains.
C. Tool Interoperability
The emergence of standard interfaces (like LangChain Expression Language or LLM Router APIs) will encourage better interoperability between tools and models.
D. Hybrid LLM Management Platforms
We’ll see more all-in-one platforms that combine prompt versioning, fine-tuning, RAG, cost monitoring, and deployment — possibly inspired by what W&B or Hugging Face is doing.
E. Open Source vs SaaS Balance
A vibrant mix of open-source tools (LangChain, Chainlit, LlamaIndex) and enterprise SaaS tools (Promptable, Helicone) will continue, each serving different user bases.
Conclusion
The rise of LLM Ops and Prompt Engineering tools is not a trend — it’s a transformation. They are no longer “nice to have” tools for hobbyists and tinkerers. They are now mission-critical components in building reliable, scalable, and ethical AI systems. Teams that succeed with AI are those who treat prompts as code, LLMs as infrastructure, and outputs as products to be tested, improved, and deployed. Investing in the right tools now is the difference between building experimental chatbots and building transformative, intelligent systems. Whether you're a developer, researcher, or startup founder, the tools outlined here provide you the building blocks to create AI applications that are faster, smarter, and more accountable than ever before.
























